K Nearest Neighbors
Jim Rohn once said, “you are the average of the five people you spend the most time with”. Jim said this from the perspective of an American entrepreneur. Lots of software engineers would agree with him since he is also talking about one of the best known algorithm in machine learning: k-nearest neighbors (abbreviated as kNN).
Let’s see a very simple example.
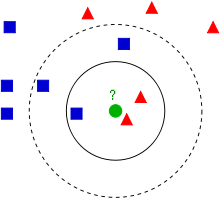
In the figure above, we are the green point, we have friends that are either blue or red, and we choose to be blue or red by following our closest friends. Although Jim said that we are the average of 3 best friends, 3 is not a fixed number in kNN algorithm. We can be an average of any odd number of friends.
Let’s say, we are the average of 3 friends. Among the 3 closest friends, we have 2 red friends and 1 blue friend, and by voting we choose to be red.
How about we choose to be the average of 5 closest friends? We expand our friend circle, and get 2 more blue friends. Now we have 3 blue friends and 2 red friends. By voting, we decide to be blue this time.
Now the idea is quite clear. Usually a classifier has two steps, so let’s explain kNN also in two steps:
- train This step basically puts data into the class without doing any preprocessing
- predict This steps is the juicy part where it finds the k closest neighbors to the input and predict the result basedon the labels of the k closest neighbors.
For the code, check below.
import math
from heapq import nsmallest
from collections import defaultdict
class kNN(object):
def __init__(self, k):
if k <= 0 or k % 2 != 1:
raise Exception("k must be a positive odd integer")
self.k = k
self.neighbors = []
self.labels = []
def train(self, neighbors, labels):
# dimensions must match
if len(neighbors) != len(labels):
raise Exception("dimensions of neighbors and labels are different")
self.neighbors.extend(neighbors)
self.labels.extend(labels)
def predict(self, new_neighbor):
distances = []
# calculate the distances between this neighbor and all other neighbors
for i in range(len(self.neighbors)):
dist = self._distance(self.neighbors[i], new_neighbor)
distances.append([i, dist])
# nsmallest picks the n smallest element from a dataset. The idea is build a min-heap and pop out k elements.
distances = nsmallest(self.k, distances, key=lambda x: x[1])
# find the indices of k closest neighbors
closest = [item[0] for item in distances]
# find which label appears the most frequently among your k closest neighbors
votes = defaultdict(int)
for i in range(len(closest)):
votes[self.labels[closest[i]]] += 1
return max(votes, key=lambda x: votes[x])
def _distance(self, inst1, inst2):
# calculate the Euclidean distance between two points
if len(inst1) != len(inst2):
raise Exception("dimension of neighbors are different")
dist = 0
for i in range(len(inst1)):
dist += (inst1[i] - inst2[i]) * (inst1[i] - inst2[i])
return math.sqrt(dist)
if __name__ == "__main__":
classifier = kNN(3)
classifier.train([[-2, 5, 2], [-1, 4, 0], [5, 8, 4], [3, -1, 2]], ['blue', 'blue', 'red', 'red'])
print classifier.predict([-1, 2, 0])
print classifier.predict([5, 9, 4])